- Overwatch Gameplay Architecture and Netcode
- Timothy Ford
- Lead Gameplay Engineer
- Blizzard Entertainment
- 翻译:kevinan
在GDC2017【Overwatch Gameplay Architecture andNetcode 】的分享会上,来自暴雪的Tim Ford介绍了《守望先锋》游戏架构和网络同步的设计。一起来看看吧。



哈喽,大家好,这次的分享是关于《守望先锋》(译注:下文统一简称为Overwatch)游戏架构设计和网络部分。老规矩,手机调成静音;离开时记得填写调查问卷;换下半藏,赶紧推车!(众笑)
我是Tim Ford,是暴雪公司Overwatch开发团队老大。自从2013年夏季项目启动以来就在这个团队了。在那之前,我在《Titan》项目组,不过这次分享跟Titan没有半毛钱关系。(众笑)
这次分享的一些技术,是用来降低不停增长的代码库的复杂度(译注,代码复杂度的概念需要读者自行查阅)。为了达到这个目的我们遵循了一套严谨的架构。最后会通过讨论网络同步(netcode)这个本质很复杂的问题,来说明具体如何管理复杂性。
Overwatch是一个近未来世界观的在线团队英雄射击游戏,它的主要是特点是英雄的多样性, 每个英雄都有自己的独门绝技。

Overwatch使用了一个叫做“实体组件系统”的架构,接下来我会简称它为ECS。

ECS不同于一些现成引擎中很流行的那种组件模型,而且与90年代后期到21世纪早期的经典Actor模式区别更大。我们团队对这些架构都有多年的经验,所以我们选择用ECS有点是“这山望着那山高”的意味。不过我们事先制作了一个原型,所以这个决定并不是一时冲动。
开发了3年多以后,我们才发现,原来ECS架构可以管理快速增长的代码复杂性。虽然我很乐意分享ECS的优点,但是要知道,我今天所讲的一切其实都是事后诸葛亮 。
ECS架构概述
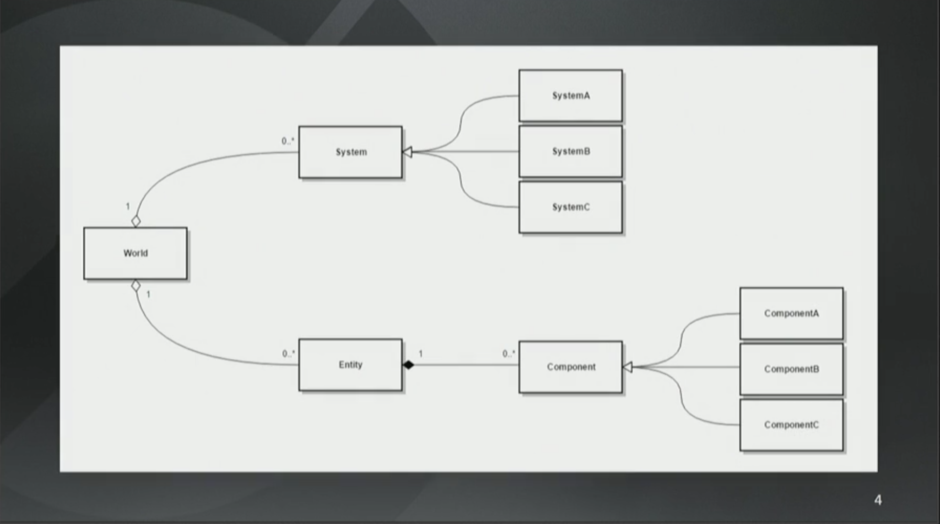
ECS架构看起来就是这样子的。先有个World,它是系统(译注,这里的系统指的是ECS中的S,不是一般意义上的系统,为了方便阅读,下文统称System)和实体(Entity)的集合。而实体就是一个ID,这个ID对应了组件(Component)的集合。组件用来存储游戏状态并且没有任何的行为(Behavior)。System有行为但是没有状态。
这听起来可能挺让人惊讶的,因为组件没有函数而System没有任何字段。
ECS引擎用到的System和组件
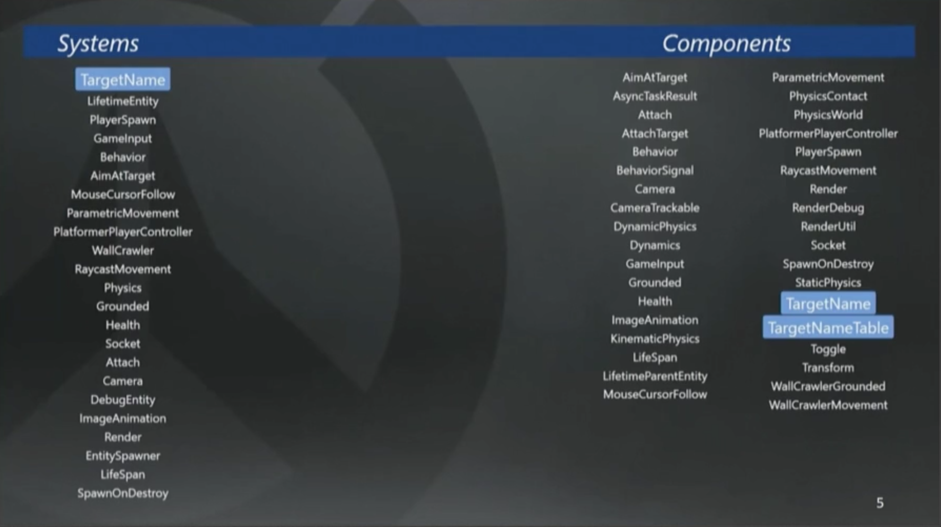
图的左手边是以轮询顺序排列的System列表,右边是不同实体拥有的组件。在左边选择不同的System以后,就像弹钢琴一样,所有对应的组件会在右边高亮显示,我们管这叫组件元组(译注,元组tuple,从后文来看,主要作用就是可以调用Sibling函数来获取同一个元组内的组件,有点虚拟分组的意思)。
System遍历检查所有元组,并在其状态(State)上执行一些操作(也就是行为Behavior)。记住组件不包含任何函数,它的状态都是裸存储的。
绝大多数的重要System都关注了不止一个组件,如你所见,这里的Transform组件就被很多System用到。
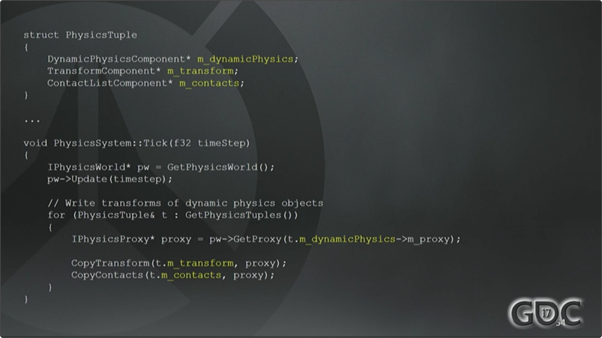
来自原型引擎里的一个System轮询(tick)的例子
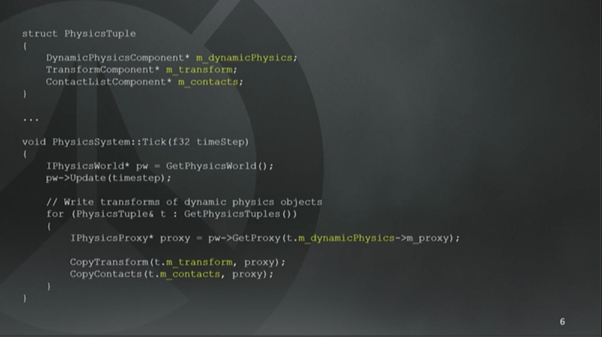
这个是物理System的轮询函数,非常直截了当,就是一个内部物理引擎的定时更新。物理引擎可能是Box2d或者是Domino(暴雪自有物理引擎)。执行完物理世界的模拟以后,就遍历元组集合。用DynamicPhysicsComponent组件里保存的proxy来取到底层的物理表示,并把它复制给Transform组件和Contact组件(译注:碰撞组件,后文会大量用到)。
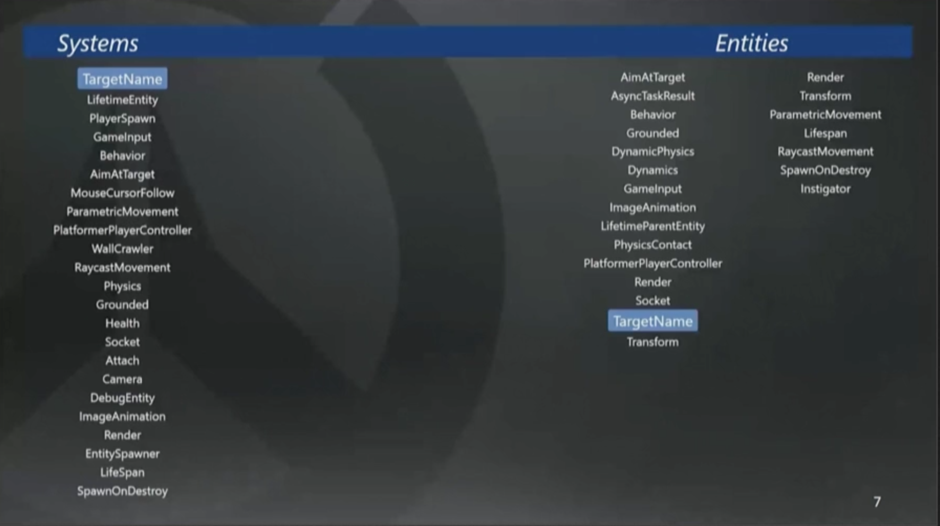
System不知道实体到底是什么,它只关心组件集合的小切片(slice,译注:可以理解为特定子集合),然后在这个切片上执行一组行为。有些实体有多达30个组件,而有些只有2、3个,System不关心数量,它只关心执行操作行为的组件的子集。
像这个原型引擎里的例子,(指着上图7中)这个是玩家角色实体,可以做出很多很酷的行为,右边这些是玩家能够发射的子弹实体。
每个System在运行时,不知道也不关心这些实体是什么,它们只是在实体相关组件的子集上执行操作而已。
Overwatch里的(ECS架构的)实现,就是这样子的。
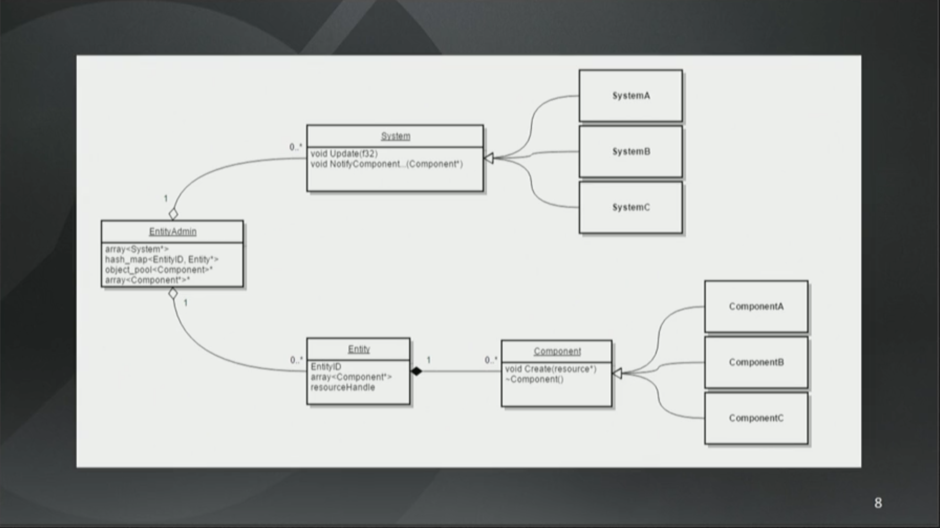
EntityAdmin是个World,存储了一个所有System的集合,和一个所有实体的哈希表。表键是实体的ID。ID是个32位无符号整形数,用来在实体管理器(Entity Array)上唯一标识这个实体。另一方面,每个实体也都存了这个实体ID和资源句柄(resource handle),后者是个可选字段,指向了实体对应的Asset资源(译注:这需要依赖暴雪的另一套专门的Asset管理系统),资源定义了实体。
组件Component是个基类,有几百个子类。每个子类组件都含有在System上执行Behavior时所需的成员变量。在这里多态唯一的用处就是重载Create和析构(Destructor)之类的生命周期管理函数。而其他能被继承组件类实例直接使用的,就只有一些用来方便地访问内部状态的helper函数了。但这些helper函数不是行为(译注:这里强调是为了遵循前面提到的原则:组件没有行为),只是简单的访问器。
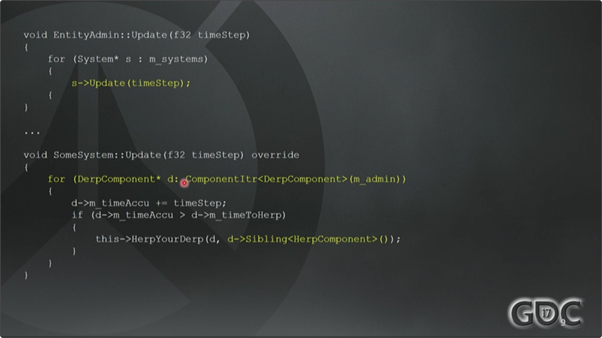
EntityAdmin的结尾部分会调用所有System的Update。每个System都会做一些工作。上图9就是我们的使用方式,我们没有在固定的元组组件集合上执行操作,而是选择了一些基础组件来遍历,然后再由相应的行为去调用其他兄弟组件。所以你可以看到这里的操作只针对那些含有Derp和Herp组件的实体的元组执行。
Overwatch客户端的System和组件列表

这里有大概46不同的System和103个组件。这一页的炫酷动画是用来吸引你们看的(众笑)。
然后是服务器

你可以看到有些System执行需要很多组件,而有些System仅仅需要几个。理想情况下,我们尽量确保每个System都依赖很多组件去运行。把他们当成纯函数(译注,pure function,无副作用的函数),而不改变(mutating)它们的状态,就可以做到这一点。我们的确有少量的System需要改变组件状态,这种情况下它们必须自己管理复杂性。
下面是个真实的System代码
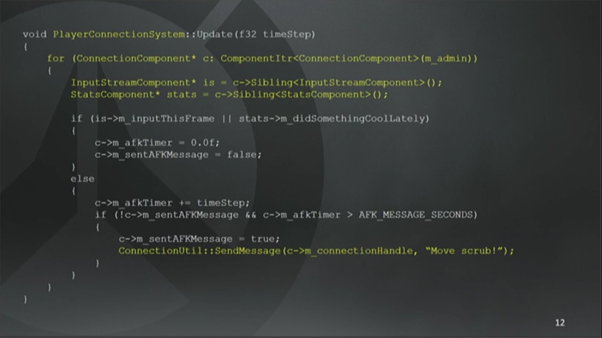
这个System是用来管理玩家连接的,它负责我们所有游戏服务器上的强制下线(译注,AFK, Away From Keyboard,表示长时间没操作而被认为离线)功能。
这个System遍历所有的Connection组件(译注:这里不太合适直接翻译成“连接”),Connection组件用来管理服务器上的玩家网络连接,是挂在代表玩家的实体上的。它可以是正在进行比赛的玩家、观战者或者其他玩家控制的角色。System不知道也不关心这些细节,它的职责就是强制下线。
每一个Connection组件的元组包含了输入流(InputStream)和Stats组件(译注:看起来是用来统计战斗信息的)。我们从输入流组件读入你的操作,来确保你必须做点什么事情,例如键盘按键;并从Stats组件读取你在某种程度上对游戏的贡献。
你只要做这些操作就会不停重置AFK定时器,否则的话,我们就会通过存储在Connection组件上的网络连接句柄发消息给你的客户端,踢你下线。
System上运行的实体必须拥有完整的元组才能使得这些行为能够正常工作。像我们游戏里的机器人实体就没有Connection组件和输入流组件,只有一个Stats组件,所以它就不会受到强制下线功能的影响。System的行为依赖于完整集合的“切片”。坦率来说,我们也确实没必要浪费资源去让强制机器人下线。
为什么不能直接用传统面向对象编程模型?

上面System的更新行为会带来了一个疑问:为什么不能使用传统的面向对象编程(OOP)的组件模型呢?例如在Connection组件里重载Update函数,不停地跟踪检测AFK?
答案是,因为Connection组件会同时被多个行为所使用,包括:AFK检查;能接收网络广播消息的已连接玩家列表;存储包括玩家名称在内的状态;存储玩家已解锁成就之类的状态。所以(如果用传统OOP方式的话)具体哪个行为应该放在组件的Update中调用?其余部分又应该放在哪里?
传统OOP中,一个类既是行为又是数据,但是Connection组件不是行为,它就只是状态。Connection完全不符合OOP中的对象的概念,它在不同的System中、不同的时机下,意味着完全不同的事情。
那么把行为和状态区分开,又有什么理论上的优势(conceptual advantages)呢?

想象一下你家前院盛开的樱桃树吧,从主观上讲,这些树对于你、你们小区业委会主席、园丁、一只鸟、房产税官员和白蚁而言都是完全不同的。从描述这些树的状态上,不同的观察者会看见不同的行为。树是一个被不同的观察者区别对待的主体(subject)。

类比来说,玩家实体,或者更准确地说,Connection组件,就是一个被不同System区别对待的主体。我们之前讨论过的管理玩家连接的System,把Connection组件视为AFK踢下线的主体;连接实用程序(ConnectUtility)则把Connection组件看作是广播玩家网络消息的主体;在客户端上,用户界面System则把Connection组件当做记分板上带有玩家名字的弹出式UI元素主体。
Behavior为什么要这么搞?结果看来,根据主体视角区分所有Behavior,这样来描述一棵树的全部行为会更容易,这个道理同样也适用于游戏对象(game objects)。
然而随着这个工业级强度的ECS架构的实现,我们遇到了新的问题。
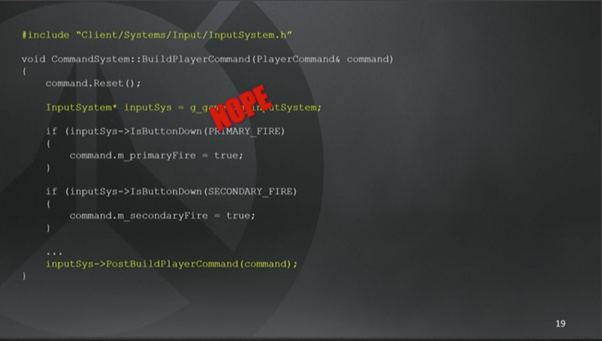
首先我们纠结于之前定下的规矩:组件不能有函数;System不能有状态。显而易见地,System应该可以有一些状态的,对吧?一些从其他非ECS架构导入的遗留System都有成员变量,这有什么问题吗?举个例子,InputSystem, 你可以把玩家输入信息保存在InputSystem里,而其他System如果也需要感知按键是否被按下,只需要一个指向InputSystem的指针就能实现。
在单个组件里存储一个全局变量看起来很很愚蠢,因为你开发一个新的组件类型,不可能只实例化一次(译注:这里的意思是,如果实例化了多次,就会有多份全局变量的拷贝,明显不合理),这一点无需证明。组件通常都是按照我们之前看见过的那种方式(译注:指的是通过ComponentItr<>函数模板那种方式)来迭代访问,如果某个组件在整个游戏里只有一个实例,那这样访问就会看起来比较怪异了。
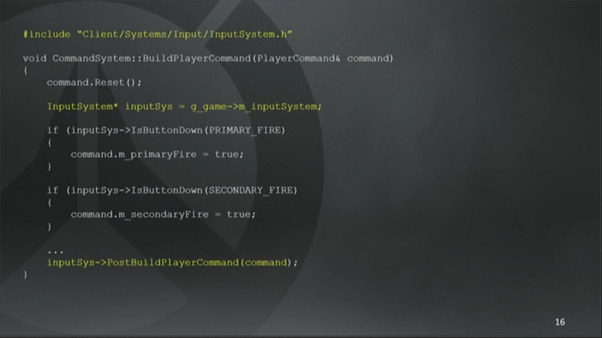
无论如何,这种方式撑了一阵子。我们在System里存储了一次性(one-off)的状态数据,然后提供了一个全局访问方式。从图16可以看到整个访问过程(译注:重点是g_game->m_inputSystem这一行)。
如果一个System可以调用另外一个System的话,对于编译时间来说就不太友好了,因为System需要互相包含(include)。假定我现在正在重构InputSystem,想移动一些函数,修改头文件(译注:Client/System/Input/InputSystem.h),那么所有依赖这个头文件去获取输入状态的System都需要被重新编译,这很烦人,还会有大量的耦合,因为System之间互相暴露了内部行为的实现。(译注:转载不注明出处,真的大丈夫吗?还把译者的名字都删除!声明:这篇文章是本人kevinan应GAD要求而翻译!)
从图16最下面可以看见我们有个PostBuildPlayerCommand函数,这个函数是InputSystem在这里的主要价值。如果我想在这个函数里增加一些新功能,那么CommandSystem就需要根据玩家的输入,填充一些额外的结构体信息发给服务器。那么我这个新功能应该加到CommandSystem里还是PostBuildPlayerCommand函数里呢?我正在System之间互相暴露内部实现吗?
随着系统的增长,选择在何处添加新的行为代码变得模棱两可。上面CommandSystem的行为填充了一些结构体,为什么要混在一起?又为什么要放到这里而不是别处?
无论如何,我们就这样凑合了好一阵子,直到死亡回放(Killcam)需求的出现。
为了实现Killcam,我们会有两个不同的、并行的游戏环境,一个用来进行实时游戏过程渲染,一个用来专门做Killcam。我接下来会展示它们是如何实现的。
首先,也很直接,我会添加第二个全新的ECS World,现在就有两个World了,一个是liveGame(正常游戏),一个是replayGame用来实现回放(Replay)。
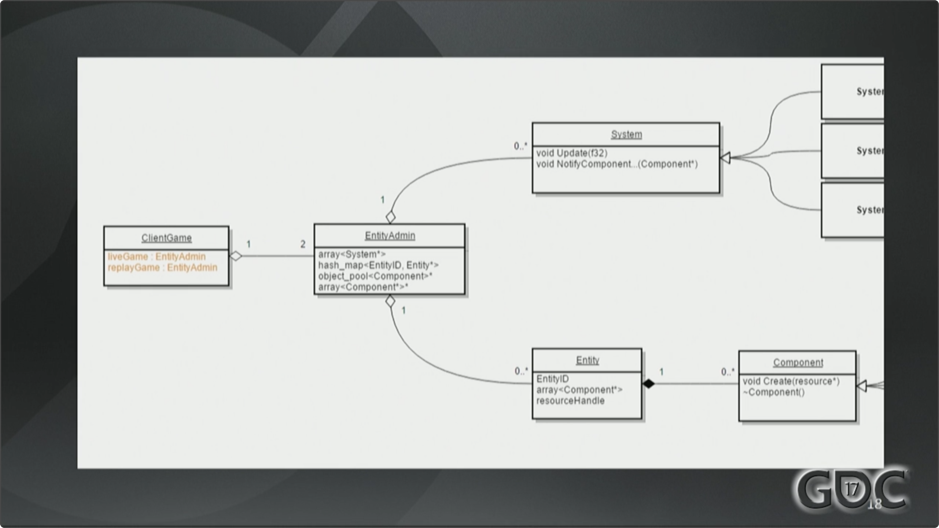
回放(Replay)的工作方式是这样的,服务器会下发大概8到12秒左右的网络游戏数据,接着客户端翻转World,开始渲染replayAdmin这个World的信息到玩家屏幕上。然后转发网络游戏数据给replayAdmin,假装这些数据真的是来自网络的。此时,所有的System,所有的组件,所有的行为都不知道它们并没有被预测(predict,译注:后面才讲到的同步技术),它们以为客户端就是实时运行在网络上的,像正常游戏过程一样。
听起来很酷吧?如果有人想要了解更多关于回放的技术,我建议你们明天去听一下Phil Orwig的分享,也是在这个房间,上午11点整。
无论如何,到现在我们已经知道的是:首先,所有需要全局访问System的调用点(call sites)会突然出错(译注:Tim思维太跳跃了,突然话锋一转,完全跟不上);另外,不再只有唯一一个全局EntityAdmin了,现在有两个;System A无法直接访问全局System B,不知怎地,只能通过共享的EntityAdmin来访问了,这样很绕。
在Killcam之后,我们花了很长时间来回顾我们的编程模式的缺陷,包括:怪异的访问模式;编译周期太长;最危险的是内部系统的耦合。看起来我们有大麻烦了。
针对这些问题的最终解决方案,依赖于这样一个事实:开发一个只有唯一实例的组件其实没什么不对!根据这个原则,我们实现了一个单例(Singleton)组件。

这些组件属于单一的匿名实体,可以通过EntityAdmin直接访问。我们把System中的大部分状态都移到了单例中。
这里我要提一句,只需要被一个System访问的状态其实是很罕见的。后来在开发一个新System的过程中我们保持了这个习惯,如果发现这个系统需要依赖一些状态。就做一个单例来存储,几乎每一次都会发现其他一些System也同样需要这些状态,所以这里其实已经提前解决了前面架构里的耦合问题。
下面是一个单例输入的例子。

全部按键信息都存在一个单例里面,只是我们把它从InputSystem中移出来了。任何System如果想知道按键是否按下,只需要随便拿一个组件来询问(那个单例)就行了。这样做以后,一些很麻烦的耦合问题消失了,我们也更加遵循ECS的架构哲学了:System没有状态;组件不带行为。
按键并不是行为,掌管本地玩家移动的Movement System里有一个行为,用这个单例来预测本地玩家的移动。而MovementStateSystem里有个行为是把这些按键信息打包发到服务器(译注:按键对于不同的System就不是不同的主体)。
结果发现,单例模式的使用非常普遍,我们整个游戏里的40%组件都是单例的。
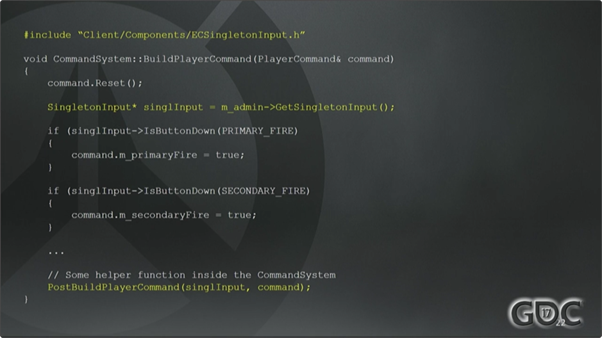
一旦我们把某些System状态移到单例中,会把共享的System函数分解成Utility(实用)函数,这些函数需要在那些单例上运行,这又有点耦合了,我们接下来会详细讨论。
改造后如图22,InputSystem依然存在(译注:然而并没有看到InputSystem在哪里),它负责从操作系统读取输入操作,填充SingletonInput的值,然后下游的其他System就可以得到同样的Input去做它们想做的。
像按键映射之类的事情就可以在单例里实现,就与CommandSystem解耦了。
我们把PostBuildPlayerCommand函数也挪到了CommandSysem里,本应如此,现在可以保证所有对玩家输入的命令(PlayerCommand)的修改都能且仅能在此处进行了。这些玩家命令是很重要的数据结构,将来会在网络上同步并用来模拟游戏过程。
在引入单例组件时,我们还不知道,我们其实正在打造的是一个解耦合、降低复杂度的开发模式。在这个例子中,CommandSystem是唯一一处能够产生与玩家输入命令相关副作用的地方(译注:sideeffect,指当调用函数时,除了返回函数值之外,还对主调用函数产生附加影响,例如修改全局变量了)。
每个程序员都能轻易地了解玩家命令的变化,因为在一次System更新的同一时刻,只有这一处代码有可能产生变化。如果想添加针对玩家命令的修改代码,那也很明朗,只能在这个源文件中改,所有的模棱两可都消失了。
现在讨论另外一个问题,与共享行为(sharedbehavior)有关。

共享行为一般出现在同一行为被多个System用到的时候。
有时,同一个主体的两个观察者,会对同一个行为感兴趣。回到前面樱花树的例子,你的小区业委会主席和园丁,可能都想知道这棵树会在春天到来的时候,掉落多少叶子。
根据这个输出可以做不同的处理,至少主席可能会冲你大喊大叫,园丁会老老实实回去干活,但是这里的行为是相同的。

举个例子,大量代码都会关心“敌对关系”,例如,实体A与实体B互相敌对吗?敌对关系是由3个可选组件共同决定的:filter bits,pet master和pet。filter bits存储队伍编号(team index);pet master存储了它所拥有全部pet的唯一键;pet一般用于像托比昂的炮台之类。
如果2个实体都没有filter bits,那么它们就不是敌对的。所以对于两扇门来说,它们就不是敌对的,因为它们的filter bits组件没有队伍编号。
如果它们(译注:2个实体)都在同一个队伍,那自然就不是敌对的,这很容易理解。
如果它们分别属于永远敌对的2个队伍,它们会同时检查自己身上和对方身上的pet master组件,确保每个pet都和对方是敌对关系。这也解决了一个问题:如果你跟每个人都是敌对的,那么当你建造一个炮台时,炮台会立马攻击你(译注:完全没理解为什么会这样)。确实会的,这是个bug,我们修复了。(众笑)
如果你想检查一枚飞行中的炮弹的敌对关系,只需要回溯检查射出这枚炮弹的开火者就行了,很简单。
这个例子的实现,其实就是个函数调用,函数名是CombatUtilityIsHostile,它接受2个实体作为参数,并返回true或者false来代表它们是否敌对。无数System都调用了这个函数。

图25中就是调用了这个函数的System,但是如你所见,只用到了3个组件,少得可怜,而且这3个组件对它们都是只读的。更重要的是,它们是纯数据,而且这些System绝不会修改里面的数据,仅仅是读。
再举一个用到这个函数的例子。

作为一个例子,当用到共享行为的Utility函数时我们采用了不同的规则。
如果你想在多处调用一个Utility函数,那么这个函数就应该依赖很少的组件,而且不应该带副作用或者很少的副作用。如果你的Utility函数依赖很多组件,那就试着限制调用点的数量。
我们这里的例子叫做CharacterMoveUtil,这个函数用来在游戏模拟过程中的每个tick里移动玩家位置。有两处调用点,一处是在服务器上模拟执行玩家的输入命令,另一处是在客户端上预测玩家的输入。

我们继续用Utility函数替换 System间的函数调用,并把状态从System移到单例组件中。
如果你打算用一个共享的Utility函数替换System间的函数调用,是不可能自动地(magically)避免复杂性的,几乎都得做语句级的调整。
正如你可以把副作用都隐藏在那些公开访问的System函数后面一样,你也可以在Utility函数后面做同样的事。
如果你需要从好几处调用那些Utility函数,就会在整个游戏循环中引入很多严重的副作用。虽然是在函数调用后面发生的,看起来没那么明显,但这也是相当可怕的耦合。
如果本次分享只让你学到一点的话,那最好是:如果只有一个调用点,那么行为的复杂性就会很低,因为所有的副作用都限定到函数调用发生的地方了。
下面浏览一下我们用来减少这类耦合的技术。

当你发现有些行为可能产生严重的副作用,又必须执行时,先问问你自己:这些代码,是必须现在就执行吗?
好的单例组件可以通过“推迟”(Deferment)来解决System间耦合的问题。“推迟”存储了行为所需状态,然后把副作用延后到当前帧里更好的时机再执行。
例如,代码里有好多调用点都要生成一个碰撞特效(impact effects)。
包括hitscan(译注:直射,没有飞行时间)子弹;带飞行时间的可爆炸抛射物;查里娅的粒子光束,光束长得就像墙壁裂缝,而且在开火时需要保持接触目标;另外还有喷涂。
创建碰撞特效的副作用很大,因为你需要在屏幕上创建一个新的实体,这个实体可能间接地影响到生命周期、线程、场景管理和资源管理。
碰撞特效的生命周期,需要在屏幕渲染之前就开始,这意味着它们不需要在游戏模拟的中途显现,在不同的调用点都是如此。
下图30是用来创建碰撞特效的一小部分代码。基于Transform(译注:变形,包括位移旋转和缩放)、碰撞类型、材质结构数据来做碰撞计算,而且还调用了LOD、场景管理、优先级管理等,最终生成了所需的特效。

这些代码确保了像弹孔、焦痕持久特效不会很奇怪的叠在一起。例如,你用猎空的枪去射击一面墙,留下了一堆麻点,然后法老之鹰发出一枚火箭弹,在麻点上面造成了一个大面积焦痕。你肯定想删了那些麻点,要不然看起来会很丑,像是那种深度冲突(Z-Fighting)引起的闪烁。我可不想在到处去执行那个删除操作,最好能在一处搞定。
我得修改代码了,但是看上去好多啊,调用点一大堆,改完了以后每一处都需要测试。而且以后英雄越来越多,每个人都需要新的特效。然后我就到处复制粘贴这个函数的调用,没什么大不了的,不就是个函数调用嘛,又不是什么噩梦。(众笑)
其实这样做以后,会在每个调用点都产生副作用的。程序员就得花费更多脑力来记住这段代码是如何运作的,这就是代码复杂度所在,肯定是应该避免的。
于是我们有了Contact单例。

它包含了一个未决的碰撞记录的数组,每个记录都有足够的信息,来在本帧的晚些时候创建那个特效。如果你想要生成一个特效的时候,只需要添加一条新记录并填充数据就可以了。等运行到帧的后期,进行场景更新和准备渲染的时候,ResolveContactSystem会遍历数组,根据LOD规则生成特效并互相叠加。这样的话,即使有严重的副作用,在每一帧也只是发生在一个调用点而已。
除了降低复杂度以外,“推迟”方案还有很多其他优点。数据和指令都缓存在本地,可以带来性能提升;你可以针对特效做性能预算了,例如你有12个D.VA同时在射墙,她们会带来数百个特效,你不用立即创建全部这些特效,你可以仅仅创建自己操纵的D.VA的特效就可以了,其他特效可以在后面的运算过程中分摊开来,平滑性能毛刺。这样做有很多好处,真的,你现在可以实现一些复杂的逻辑了。即使ResolveContactSystem需要执行多线程协作,来确定单个粒子效果的朝向, 现在也很容易做。“推迟”技术真的很酷。
Utility函数,单例,推迟,这些都只是我们过去3年时间建立ECS架构的一小部分模式。除了限制System中不能有状态,组件里不能有行为以外,这些技术也规定了我们在Overwatch中如何解决问题。

遵守这些限制意味着你要用很多奇技淫巧来解决问题。不过,这些技术最终造就了一个可持续维护的、解耦合的、简洁的代码系统。它限制了你,它把你带到坑里,但这是个“成功之坑”。
学习了这些之后呢,咱们来聊聊真正的难题之一,以及ECS是如何简化它的。

作为gameplay(游戏玩法,机制)工程师,我们解决过的最重要的问题就是网络同步(netcode)。
这里先说下目标,是要开发一款快速响应(responsive)的网络对战动作游戏。为了实现快速响应,就必须针对玩家的操作做预测(predict,也可以说是预表现)。如果每个操作都要等服务器回包的话,就不可能有高响应性了。尽管因为一些混蛋玩家作弊所以不能信任客户端,但是已经20年了,这条FPS游戏真理没变过。
游戏中有快速响应需求的操作包括:移动,技能,就我们而言还有带技能的武器,以及命中判定(hit registration)。
这里所有的操作都有统一的原则:玩家按下按键后必须立即能够看到响应。即使网络延迟很高时也必须是如此。
像我这页PPT中演示的那样,ping值已经250ms了,我所有的操作也都是立即得到反馈的,“看上去”很完美,一点延迟都没有。
然而呢,带预测的客户端,服务器的验证和网络延迟就会带来副作用:预测错误(misprediction,或者说预测失败)了。预测错误的主要症状就一点,会使得你没能成功执行“你认为你已经做出的”操作。
虽然服务器需要纠正你的操作,但代价并不会是操作延迟。我们会用”确定性”(Determinism)来减少预测错误发生的概率,下面是具体的做法。
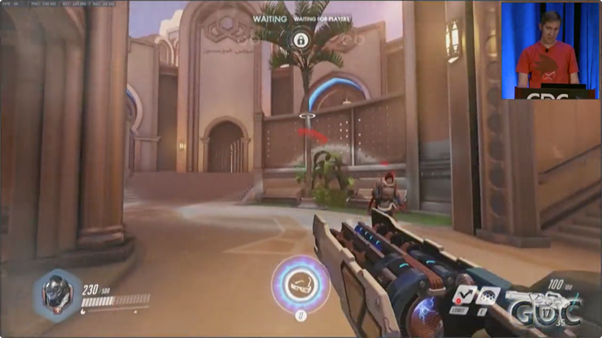
前提条件不变,PING值还是250毫秒。我认为我跳起来了,但是服务器不这么看,我被猛拉回原地,而且被冻住了(冰冻是英雄Mei的技能之一)。这里(PPT中视频演示)你甚至可以看到整个预测的工作过程。预测过程开始时,试图把我们移到空中,甚至大猩猩跳跃技能的CD都已经进入冷却了,这是对的,我们不希望预测准确率仅仅是十之八九。所以我们希望尽可能的快速响应,
如果你碰巧在斯里兰卡玩这个游戏,而且又被Mei冻住了,那么就有可能会预测错误。

下面我会首先给出一些准则,然后讨论一下这个崭新的技术是如何利用ECS来减少复杂度的。
这里不会涉及到通用的数据复制技术、远端实体插值(remote entity interpolation)或者是向后缓和(backwardsreconciliation)技术细节。
我们完全是站在巨人的肩膀上,使用了一些其他文献中提过的技术而已。后面的幻灯片会假定大家对那些技术都已经很熟悉了。
确定性(Determinism)

确定性模拟技术依赖于时钟的同步,固定的更新周期和量化。服务器和客户端都运行在这个保持同步的时钟和量化值之上。时间被量化成command frame,我们称之为“命令帧”。每个命令帧都是固定的16毫秒,不过在电竞比赛时是7毫秒。

模拟过程的频率是固定的,所以需要把计算机时钟循环转换为固定的命令帧序号。我们使用了一个循环累加器来处理帧号的增长。
在我们的ECS框架内,任何需要进行预表现、或者基于玩家的输入模拟结果的System,都不会使用Update,而是用UpdateFixed。UpdateFixed会在每个固定的命令帧调用。
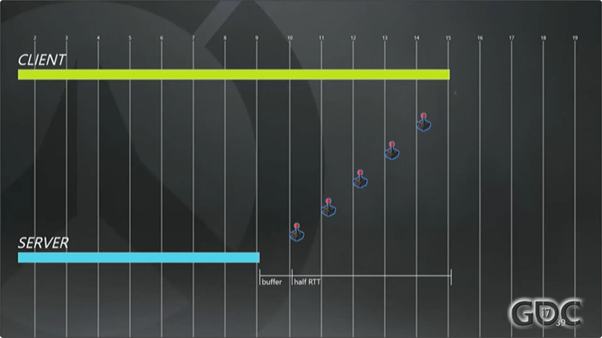
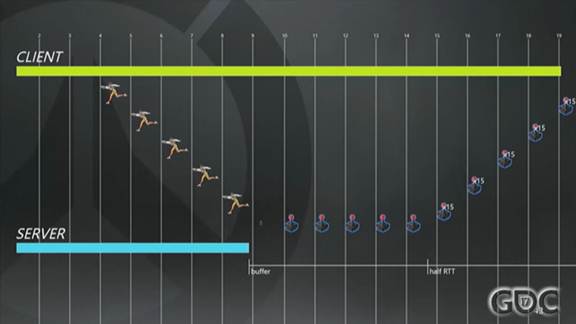
假定输出流是稳定的,那么客户端的始终总是会超前于服务器的,超前了大概半个RTT加上一个缓存帧的时长。这里的RTT是PING值加上逻辑处理的时间。上图39的例子中,我们的RTT是160毫秒,一半就是80毫秒,再加上1帧,我们每帧是16毫秒,全加起来就是客户端相对于服务器的提前量。
图中的垂直线代表每一个处理中的帧。客户端开始模拟并把第19帧的输入上报给服务器,过一段时间(基本上是半个RTT加上缓冲时间)以后,服务器才开始模拟这一帧。这就是我为什么要说客户端永远是领先于服务器的。
正因为客户端是一股脑的尽快接受玩家输入,尽可能地贴近现在时刻,如果还需要等待服务器回包才能响应的话,那看起来就太慢了,会让游戏变得卡顿。图39中的缓冲区,你肯定希望尽可能的小(译注:缓冲越小,模拟时就越接近当前时刻),顺便说一句,游戏运行的频率是60赫兹,我这里播放动画的速度是正常速度的百分之一(译注:这也是为了让观众看得更清晰、明白)。
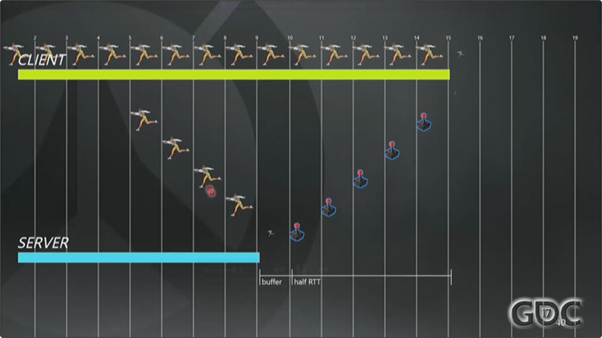
客户端的预测System读取当前输入,然后模拟猎空的移动过程。我这里是用游戏摇杆来表示猎空的输入操作并上报的。这里的(第14帧)猎空是我当前时刻模拟出来的运动状态,经过完整的RTT加上缓冲事件,最终猎空会从服务器上回到客户端(译注:这里最好结合演讲视频,静态的文章无法表达到位)。这里回来的是经过服务器验证的运动状态快照。服务器模拟权威带来的副作用就是验证需要额外的半个RTT时间才能回到客户端。
那么这里客户端为什么要用一个环形缓冲(ring buffer)来记录历史运动轨迹呢?这是为了方便与服务器返回的结果进行对比。经过比较,如果与服务器模拟结果相同,那么客户端会开开心心地继续处理下一个输入。如果结果不一致,那就是一个“预测错误”,这时就需要“和解”(reconcile)了。
如果想简单,那就直接用服务器下发的结果覆盖客户端就行了,但是这个结果已经是“旧”(相对于当前时刻的输入来讲)的了,因为服务器的回包一般都是几百毫秒之前的了。
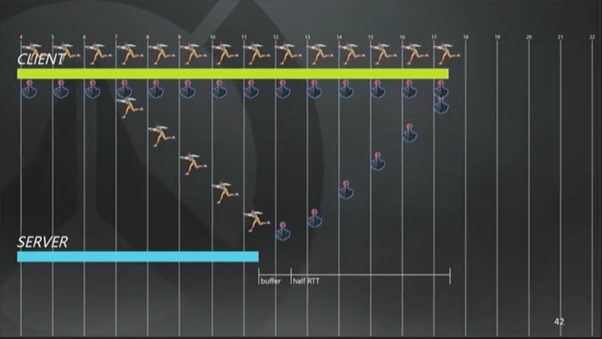
除了上面那个环形缓冲以外,我们还有另一个环形缓冲用来存储玩家的输入操作。因为处理移动的代码是确定性的,一旦玩家开始进入他想要进入到移动状态,想要重现这个过程也是很容易的。所以这里我们的处理方式就是,一旦从服务器回包发现预测失败,我们把你的全部输入都重播一遍直至追上当前时刻。如下图41中的第17帧所示,客户端认为猎空正在跑路,而服务器指出,你已经被晕住了,有可能是受到了麦克雷的闪光弹的攻击。

接下来的流程是,当客户端收到描述角色状态的数据包时,我们基本上就得把移动状态及时恢复到最近一次经过服务器验证过状态上去,而且必须重新计算之后所有的输入操作,直至追上当前时刻(第25帧)。

现在客户端进行到第27帧(上图)了,这时我们收到了服务器上第17帧的回包。一旦重新同步(译注:注意下图41中客户端猎空的状态全都更正为“晕”了)以后,就相当于回退到了“帧同步”(lockstep)算法了。
我们肯定知道我们到底被晕了多久。

到了下图第33帧以后,客户端就知道已经不再是晕住的状态了,而服务器上也正在模拟相同的情况。不再有奇怪的同步追赶问题了。一旦进入这个移动状态,就可以重发玩家当前时刻的操作输入了。

然而,客户端网络并不保证如此稳定,时有丢包发生。我们游戏里的输入都是通过定制化的可靠UDP实现。所以客户端的输入包常常无法到达服务器,也就是丢包。服务器又试图保持了一个小小的、保存未模拟输入的缓冲区,但是让它尽量的小,以保证游戏操作的流畅。
一旦这个缓冲区是空的,服务器只能根据你最后一次输入去“猜测”。等到真正的输入到达时,它会试着“缓和”,确保不会弄丢你的任何操作,但是也会有预测错误。
下面是见证奇迹的时刻。

上图可以看到,已经丢了一些来自客户端的包,服务器意识到以后,就会复制先前的输入操作来就行预测,一边祈祷希望预测正确,一边发包告诉客户端:“嘿哥们,丢包了,不太对劲哦”。接下来发生的就更奇怪的了,客户端会进行时间膨胀,比约定的帧率更快地进行模拟。
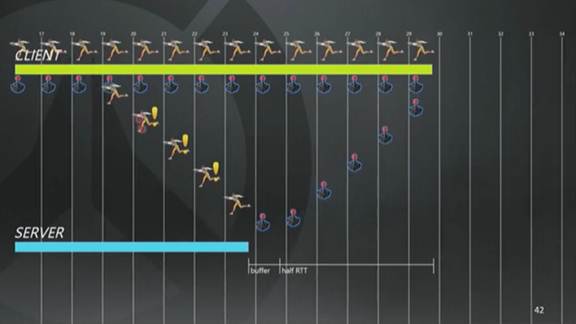
这个例子里,约定好的帧速是16毫秒,客户端就会假装现在帧速是15.2毫秒,它想要更加提前。结果就是,这些输入来的越来越快。服务器上缓冲区也会跟着变大,这就是为了在尽量不浪费的情况下,度过(丢包的)难关。
这种技术运转良好,尤其是在经常抖动的互联网环境下,丢包和PING都不稳定。即使你是在国际空间站里玩这个游戏,也是可以的。所以我想这个方案真的很NB。
现在,各位都记个笔记吧,这里收到消息,现在开始放大时间刻度,注意我们是真的加速轮询了,你可以看见图中右边的坡越来越平坦了。它比以前更加快速地上报输入。同时服务器上的缓冲也越来越大了,可以容忍更多地丢包,如果真的发生丢包也有可能在缓冲期间补上。

一旦服务器发现,你现在的网络恢复健康了,它就会发消息给你说:“嘿哥们,现在没事了”。而客户端会做相反的事情:它会缩小时间刻度,以更慢的速度发包。同时服务器会减小缓冲区的尺寸。
如果这个过程持续发生,那目标就会是是不要超过承受极限,并通过输入冗余来使得预测错误最小化。
早些时候我有提到过,服务器一旦饥饿,就会复制最后一次输入操作,对吧?一旦客户端赶上来了,就不会再复制输入了,这样会有因为丢包而被忽略的风险。解决方法是,客户端维持一个输入操作的滑动窗口。这项技术从《雷神世界》开始就有了。
我们不是仅仅发送当前第19帧的输入,而是把从最后一次被服务器确认的运动状态到现在的全部输入都发送过去。上面的例子可以看出,最后一次从服务器来的确认是第4帧。而我们刚刚模拟到了第19帧。我们会把每一帧的每一个输入都打包成为一个数据包。玩家一般顶多每1/60秒才会有一次操作,所以压缩后数据量其实不大。一般你按住“向前”按钮之前,很可能是已经在“前进”了。
结果就是,即使发生丢包,下一个数据包到达时依然会有全部的输入操作,这会在你真正模拟以前,就填充上所有因为丢包而出现的空洞。所以这个反馈循环的过程和可增长的缓冲区大小,以及滑动窗口,使得你不会因为丢包而损失什么。所以即使丢包也不会出现预测错误。
接下来会再次给你展示动画过程,这一次是双倍速,是正常速度的1/50了。
这里有全部不稳定因素:网络PING值抖动,有丢包,客户端时间刻度放大,输入窗口填充了全部漏洞,有预测失败,有服务器纠正。我们它们都合在一起播放给你看。
接下来的议题,我不想讲太多细节,因为这是Dan Reid的分享的主题(译注,已经翻译),因为这是开幕式的一部分,所以强烈推荐各位听一下,真的很棒。还是在这个房间,我讲完了就开始。
所有的技能都是用暴雪自有指令式脚本语言Statescript开发的。脚本系统的一大优点就是它可以在前后穿越时空。在客户端预测,然后服务器验证,就像之前的例子里面的移动操作,我们可以把你回滚然后重播所有输入。技能也使用了与移动相同的前后滚原则,先回退到最后一次经过验证的快照的状态,然后重播输入直到当前时刻。
大家肯定还记得这个例子,就是猎空被晕导致的服务器纠正过程,技能的处理过程是相同的。客户端和服务器都会模拟技能执行的确定性过程,客户端领先于服务器,所以一般是客户端先模拟,服务器稍后跟进。客户端处理预测错误的方式是,先根据服务器快照回滚,然后再前滚(roll forth),就像这样幻灯演示的动画过程那样。这里演示的是死神的幽灵形态。图45中的这些方块(译注:Statescript中的State)代表了幽灵形态,有了这些方块我就可以很自信的播放很酷的特效和动画了。
幽灵形态结束后就会关闭这些方块。在同一帧中这些小动画会展示出State的关闭过程。紧接着就是幽灵形态的出现,不久以后我们就会得到来自服务器的消息:“嗨,我预测的幽灵形态的过程已经告诉你了,所以你赶紧倒退回去,把这些State都打开,然后咱们再重新模拟全部输入,把这些State都关了”。这基本上就是每次服务器下发更新时回滚和前滚的过程了。
能预测移动很酷,这意味着可以预测每个技能,我们也确实这样做了,同样,对于武器或者其他的模块,我们也可以这么做。
现在讨论一下命中判定的预测和确认。

ECS处理这个其实很方便,还记得吗,实体如果拥有行为所需的组件元组,它就会是这个行为的主体。如果你的实体是敌对的(还记得我们之前讲的敌对性检查吧)而且你有一个ModifyHealthQueue组件,你就可以被别的玩家击中,这都受制于“命中判定”。
这两个组件,一个是用来检查敌对性的,一个是ModifyHealthQueue。ModifyHealthQueue是服务器记录的你身上的全部伤害和治疗。与单例Contact类似,也是延迟计算的,而且有多个调用点,这就是最大的副作用。延迟计算是因为不想在抛射物模拟途中,立即生成一大堆特效,我们选择延后。
顺便说一句,伤害,也完全不会在客户端预测,因为它们全都是骗子。
然而命中判定却是在客户端处理的。所以,如果你有一个MovementState组件,而且是一个不会被本地玩家操纵的remote对象,那你会被运动 System经过插值(interpolate)运算来重新定位。标准插值是发生在最后一次收到的两个MovementState之间的,这项技术自从《Quake》时代就有了。
System根本不在乎你是一个移动平台、炮台、门还是法老之鹰,你只需要拥有一个MovementState组件就够了,MovementState组件还要负责存储环形缓冲区,还记得环形缓冲嘛?之前用来保存那些猎空小人的位置的。
有了MovementState组件,服务器在计算命中以前,就会把你回滚到攻击者上报时你所在的那一帧,这就是向后缓和(backwards reconcilation)。这一切都与ModifyHealthQueue组件正交, ModifyHealthQueue组件决定了是否接受伤害。我们还需要倒回门、平台、车的状态,如果子弹被挡住了的话,就无所谓了。一般来说如果你是敌对的,而且有MovementState组件,你就会被倒回,而且可能会受伤。
被倒回(rewind)是被一组Utility函数操纵的行为;而受伤是MovementState组件被延迟处理时发生的另外一个行为。这两种行为独立开来,各自发生在各自的组件切片上。
射击过程有点抽象,我这里会分解一下。
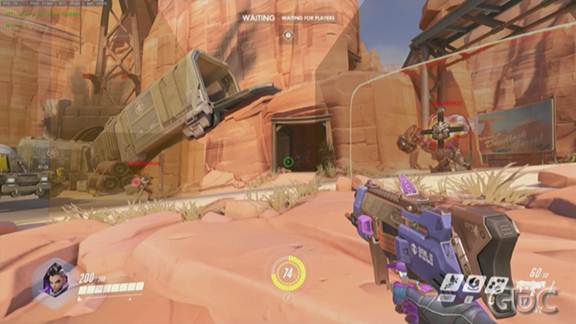
图47中的框是每一个实体的逻辑边界(bounding volumes)。逻辑边界基本上就是代表了这个源氏的实时快照的并集。所以源氏周围的逻辑边界就代表了过去半秒钟这个角色的全部运动(的最大范围)。如果我现在沿着准星方向射击,在倒回这个角色以前,会首先与这个边界相交,因为基于我的PING值,它有可能在边界内的任意一处位置。
这个例子里,如果我沿着这个方向射击,那只需要单独倒回安娜即可,因为子弹只和她的边界相交了。不需要同时倒回大锤和他的能量盾或者车,以及后面的门。
射击如同移动一样,也可能会有预测失败。
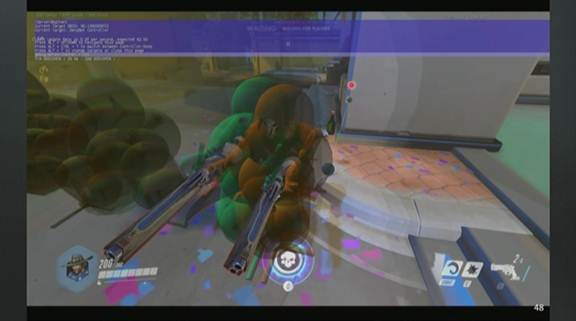
这里的绿色人偶是死神的客户端视角,黄色是服务器视角。这些绿色的小点点是客户端认为它的子弹击中的位置。可以看见绿色的细线是子弹经过的路径,但服务器在校验的时候,这个蓝紫色的半球才代表实际命中的位置。
这完全是个人为制造的例子,确定型模拟过程是很可靠的,为了重现射击过程中的预测失败,我把我的丢包率设置为60%,然后足足射了这个混蛋20分钟才成功重现(众笑)。
这里我还得提一句,模拟过程如此精确,要归功于我们的QA团队的同事。他们从不接受“NO”作为答案,而且因为市面上其他游戏都不会把命中判定的预测精确度做到这个水平,所以我们的QA小伙伴们根本不相信我,也不在乎我。只是不停地提bug单,而且是越来越多的bug单,而每一次当我们去检查是否真的有bug时,结果是每次都真的有。这里要对他们表示深深的感谢,有了他们的工作才使得我们能做出如此伟大的产品。
如果你的PING值特别高,命中判定就会失效。
一旦PING值超过220毫秒,我们就会延后一些命中效果,也不会再去预测了,直接等服务器回包确认。之所以这么做的原因是,客户端上本来就做了外插值(extrapolate),不想把目标倒回那么远。不想让受害者觉得他们拼命跑到墙后面找掩护,结果还是被回拉、受伤。所以加了一层保护。这倒回外插后一段时间内的行为。下面的视频会演示这个过程(译注:强烈建议看视频)。
PING为0的时候,对弹道碰撞做了预测,而击中点和血条没有预测,要等服务器回包才渲染。
当PING达到300毫秒的时候,碰撞都不预测了,因为射击目标正在做快读的外插,他实际上根本没在这里,这里我们用了DR(Dead Reckoning)导航推测算法,虽然很接近,但是他真没在那里。死神左右来回晃动时就会出现这种情况,外插时完全无法正确预测。这里我们不会照顾你的感受,你的网络太差了。
最后这个视频,PING达到1秒的时候,尤为明显。死神的移动方式不变,还会有外插。顺便提一句,甚至PING已经是1秒钟那么慢了,客户端的所有操作都还是能够立即预测、响应的,只不过大部分都是错的而已。其实我应该放大招的(午时已到),肯定能弄死他。
下面讲下其他预测失败的例子,PING值还是不怎么好,150毫秒。这种条件下,无论何时遇到运动预测失败,都会错误的预测命中。下面用慢动作展现一下。
看,都已经飙血了,但是却没看见血条,也没看见弹坑,所以对于弹道碰撞的预测来讲就是错误的。服务器拒绝了,这不是一次合法的命中。碰撞效果预测失败的原因就是“冰墙”立起来了。你“以为”自己开火时还站在地上,但是服务器模拟时,你已经被冰墙升到了空中,就是这个行为导致预测失败的。
当我们修复这些微小的命中预测错误时,发现大部分情况都能通过与服务器就位置问题达成一致来消除,所以我们花了很多时间来对齐位置。
下面是与运动相关的预测失败的例子,同时也与游戏玩法有关。
PING值还是150毫秒,你想射中这个死神,但是他处于幽灵形态,箭头碰到他时,客户端会预测说应该有血飚出来,没有弹坑(hit pit),也没有血条。我们根本没击中他,因为它已经先进入幽灵状态了。
这种例子里,虽然大部分时间都会优先满足进攻者,但除非受害者做了什么事情缓和(mitigate)了这次进攻。在这个例子里,死神的幽灵形态会给他3秒钟的无敌时间。无论如何,我们没有真的打到死神。
让我从哲学角度想象一下,你就是那个死神,你进入了幽灵状态,但事实上服务器很可能会让你播放所有特效,让后让你死掉,因为你不可能如此快速进入那个状态。
ECS简化了网络同步问题。网络同步代码中用到的System,知道自己何时被用于玩家身上,很简单直接,基本上如果一个实体被一个带有Connection组件的东西控制了,它就是一个玩家。
System也知道哪些目标需要被倒回到进攻者时刻的那一帧上,任何包含MovementState组件的实体都会被倒回。
实体与组件之间的内在关联主要行为是MovementState可以在时间线上被取消。
上图52是System和组件的全景图,其中只有少数几个与网络同步行为有关。而这就是我们已知最复杂的问题了。System中有两个是NetworkEvent和NetworkMessage,是网络同步模块的核心组成部分,参与了接收输入和发送输出这样的典型网络行为。
还有另外几个System,一只手就数得过来:InterpolateMovement,Weapons,Statescript,MovementState,我特别想删了MovementState,因为我不喜欢它。所以呢,实际上网络同步模块中,只有3个System是与gameplay有关的,其中用到的组件就是右边高亮列出的,也只有组件对于网络同步模块是只读的。真正修改了数据的就是像ModifyHealthQueue,因为对敌人造成的伤害是真实的。

现在回头看一下,用了ECS这么多年后,都学到了哪些知识与心得。
我有点希望System和Utility都能回到最早那个ECS操作元祖的权威例程的用法,做法有点特殊,我们只遍历一个组件就够了,再通过它访问所有兄弟组件。对于真正复杂的组件访问元组模型,你必须知道确切的访问对象才行。如果有个行为需要一个含有40个组件的元组,那可能是因为你的系统设计过于复杂了,元组之间有冲突。
元组另一个很酷的副作用是,你掌握了关于什么System能访问什么状态的先验知识,那么回到我们用到元组的那个原型引擎当中,就可以知道2或3个System可以操作不同的组件集合。因为根据元组的定义就可以知道他们的用途。这里设计的非常容易扩展。就像之前那个弹钢琴的动画一样,不过可以看到多个System同时点亮,只因为它们操纵的组件集合是不同的。

由于已经知道组件读写的优先级,System的轮询可以做到多线程处理gameplay代码。这里要提一句,Transform组件依然很受欢迎,但只有为数不多的几个System会真正修改它,大部分System都是对它只读。所以当你定义元组时,可以把组件标记上“只读”属性,这就意味着,即使有多个System都操作对该组件,但都是只读,可以并行处理。
实体生命周期管理需要一些技巧,尤其是在一帧的中间创建出来的那些。在早期,我们推迟了创建和销毁行为,当你说“嘿我想要创建一个实体时”,实际上是在那一帧结束时才完成的。事实证明,推迟销毁一点问题都没有,而推迟创建却有一大堆副作用。尤其是当你在System A 中申请创建一个新的实体,然后在System B中使用,这时如果你推迟了创建过程,你就要隔一帧才能使用。

这有点不爽。这也增加了很多内部复杂性(译注:看到这里,复杂性都是一些潜规则,需要花脑力去记住的hardcode),我们想修改掉这部分代码,使它可以在一帧的中途创建好,这样就可以马上使用了。
我们在游戏发布之后才做了这些改动,实在很恐怖。这个补丁打在了1.2或者1.3版本,上线那天晚上我都是通宵的。

我们大概花了1年半的时间来制定ECS的使用准则,就像之前那个权威的例子,但是我们需要改造一些现有的代码使之能够适应新的架构。这些准则包括:组件没有函数;System没有状态;共享代码要放到Utils里;组件里复杂的副作用要通过队列的方式推迟处理,尤其是单例组件;System不能调用其他System的函数,即使是我们自己的取名System也不行,这个System几年之前暴雪分享过的。
仍然有大量代码不符合这个规范,所以它们是复杂度和维护工作的主要来源,就一点也不奇怪了。通过检视代码变更数量或者说bug数量,你就能发现这一点。
所以,如果你有什么遗留代码而且无法融入ECS规范的话,就绝对不应该使用。保持子系统整洁,不用创建任何代理组件去对它们进行封装。
不同的系统设计是用来解决问题的不同方法。
ECS是一个集成大量System的工具,不合适的系统设计原则就不应该被采用。

ECS的设计目的是用来把大量的模块进行集成并解耦,很多 System及其依赖的组件都是冰山形状的。
冰山型组件对其他ECS的System暴露的表面很小,但它们内部其实有大量的状态、代理或者数据结构是ECS层无法访问的。
在线程模型中这些冰山的体型相当明显,大部分ECS的工作,例如更新System,都是发生在主线程(图58顶部)上的。我们也用到了大量的多线程技术,像fork和join。这个例子里,有角色发射了大量的抛射物,然后脚本System说我们需要生成一些抛射物,就创建了几个工作线程来干活。还有这里是ResolvedContactSystem想要创建一些碰撞特效,这里花费了几个工作线程去做这项工作。
抛射物模拟的幕后工作已经被隔离,而且对上层ECS是不可见的,这样很好。
另外一个很酷的例子就是AIPetDataSystem,很好的应用了fork和join模式,在ECS层面,只有一点点耦合,可能是说“嗨,这是一扇可破坏的门,你可能需要在这些区域重建路径”,但是幕后工作其实很多,像获取所有三角形,渲染并裁减,这些都与ECS无关,我们也不应该把ECS置于那些问题领域,应该自己想办法。
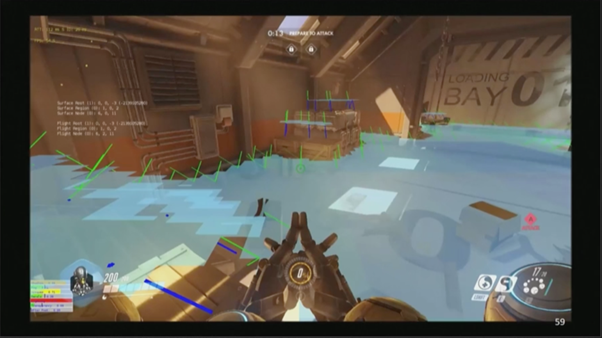
这里的视频演示的是PathValidationSystem,路径(Path)就是全部这些蓝色色块,AI可以行走于其表面上。其实路径并不只用于AI,也用在很多英雄的技能上。所以就需要在服务器和客户端之间对这些路径进行数据同步。
视频里的禅亚塔将会破坏这里的这些物品,你会看见破坏后的物体掉落到表面下方。然后那里的门会打开我们会把那些表面粘在一起。PathValidationSystem只需要说:“嗨,三角形有变化”。然后冰山背后就会用全部数据重建路径。

现在准备结束今天的分享了。
ECS是Overwatch的粘合剂,它很酷,因为它可以帮你用最小的耦合来集成大量分散的系统。如果你打算用ECS定义你的规范,实际上无论你想用什么架构来快速定义你的规范,应该都是只有少数程序员需要接触物理系统代码、脚本引擎或者音频库。但是每个人都应该能够用到胶水代码,一起集成系统。
实施这些限制,就能够马到成功。
事实证明,网络同步真的很复杂,所以必须尽可能的与引擎其余部分解耦,ECS是解决这个问题的好办法。
最后在接受提问以前,我想感谢我们团队成员,尤其是gameplay工程师,大家花了3年时间创造了如此美妙的艺术品。我们共同努力,创建原则,架构不断进化,结果也是有目共睹的。
